

oSATCo App Development:
Automation of video analysis
A placeholder description and if this description had more words
how would that look?
Pose Model (Topology)

Pose Model (Training)
- Leave portion of data for testing
- Use the rest for training
- Choose hyperparameters
- Train until convergence
- Train cycle: ~16 days (A6000 GPU)


𝑑_𝑖=√((𝑥_𝑖−𝑥_𝑖^′ )^2+(𝑦_𝑖−𝑦_𝑖^′ )^2 )Pose Analysis (Object Key-point Similarity)
d: Euclidean key-point distance
s: object scale (~0.25 x area)
k: key-point variation (~0.15)
v: key-point visibility
𝐾𝑆𝑖= 𝑒^((−(𝑑_𝑖^2)/(2𝑠^2 𝑘_𝑖^2 )) )𝑂𝐾𝑆= (∑𝐾𝑆𝑖 𝑣i)/(∑𝑣𝑖 )
OKS: 95.29% > avg. 90.96% < OKS: 86.63%

Pose Analysis (Average Precision)
APt=∑OKS> tAverage Precision at threshold of 50
AP=1/N ∑AP[0.5:0.95] Average Precision at different thresholds between 0.5 and 0.95
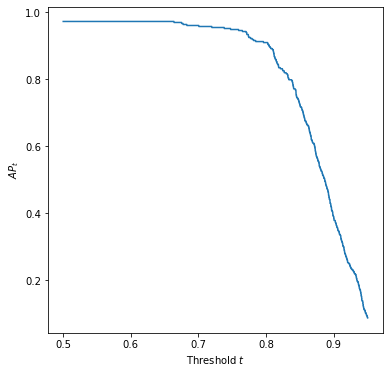
Pose Analysis (Results)


SATCo Model (Topology)

SATCo Analysis (Time-series) – 1

SATCo Analysis (Time-series) – 2

SATCo Analysis (Time-series) – 3

SATCo Analysis – Results
𝐹1=2𝑇𝑃/(2𝑇𝑃×𝐹𝑃×𝐹𝑁)Per frame results (relevant segments)

𝑟𝑎𝑛𝑘𝑖𝑗 = 𝑠𝑒𝑔𝑚𝑒𝑛𝑡𝑖 x 𝑡𝑒𝑠𝑡𝑗 x o𝑢𝑡𝑐𝑜𝑚𝑒𝐷

Low SWAP Device and Camera

